Building a simple Medical Chatbot from Vinmec Health News
- kim ngan nguyen
- Aug 19, 2023
- 5 min read

Updated: Aug 20, 2023
I have a little habit. When I notice some strange changes in my body, I would look them up on the Internet to learn about what might be causing them, the risks involved, and how they can be treated. I enjoy reading health articles on Vinmec websites because they are well written, informative and reliable. In today's article, we're going to experiment creating a medical chatbot that can help answer general health-related questions, with answers coming from more than 3000 health articles on Vinmec website. This chatbot will go through various articles from Vinmec's website and pick out the important information to put together its answers. It can understand both English and Vietnamese. To make this chatbot, I'll be using GPT-4 and Langchain. You can see how it works in the demo video.
The Architecture of the Chatbot
The below image demonstrate the architecture of our medical chatbot.
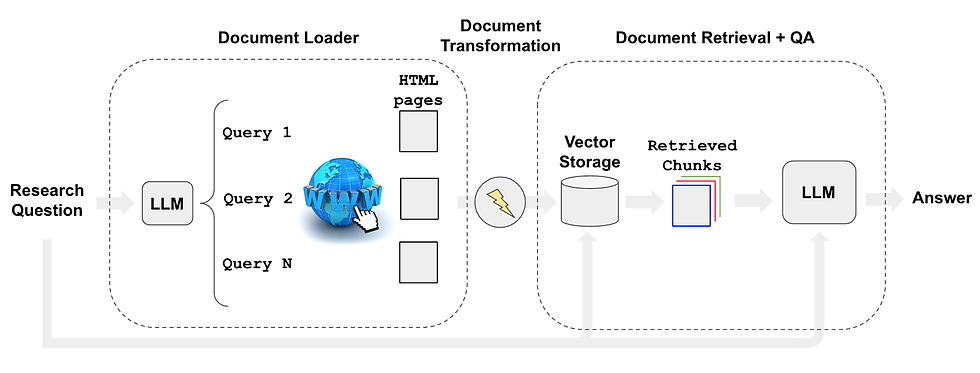
Source: LangChain. (2023). Automating web research. LangChain. https://blog.langchain.dev/automating-web-research/
The flow is described as following:
Use an LLM (here we use GPT4) to generate multiple relevant search queries (one LLM call).
Execute a search for each query to designated websites. In our case, I will use Public Health News from Vinmec website via 02 links:
For Vietnamese Articles: www.vinmec.com/vi/tin-tuc/* .
For English Articels: www.vinmec.com/en/news/health-news/*
Choose the top K links per query (multiple search calls in parallel)
Load the information from all chosen links (scrape pages in parallel)
Index those documents into a vectorstore (here we will use text-embedding-ada-002 as our embedding model and FAISS as our vectorstore)
Find the most relevant documents for each original generated search query
Step-by-Step Guidance on Building Medical Chatbot
1. Setting Google Search API
We will utilize Google Search Custom API for our queries. The Google Search custom API is a tailored solution provided by Google that allows developers to integrate Google Search functionality directly into their applications, websites, or services. It's designed to offer a seamless and personalized search experience by leveraging Google's powerful search capabilities while giving developers more control over the appearance and behavior of search results. You need to set up the proper API keys and environment variables.
Create the GOOGLE_API_KEY in the Google Cloud credential console. Link: https://console.cloud.google.com/apis/credentials
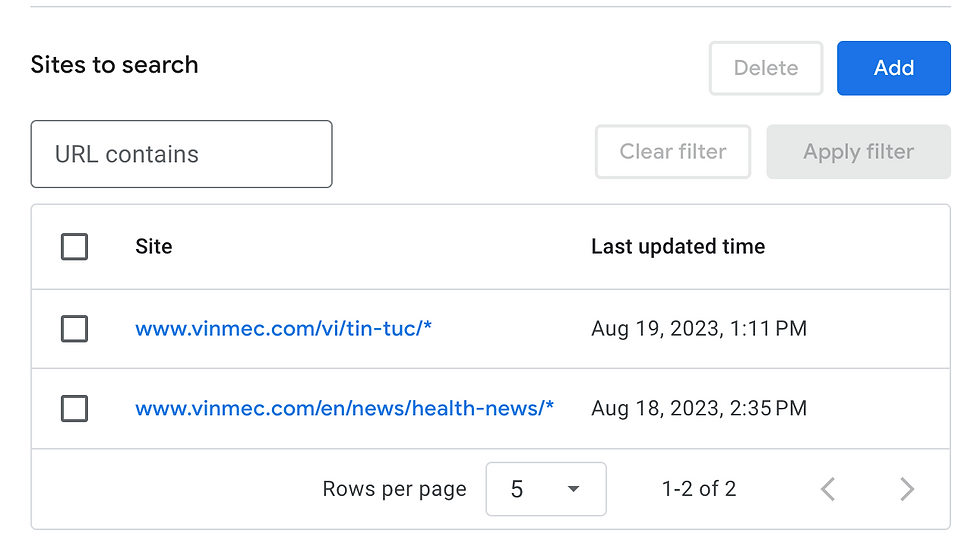
Create a GOOGLE_CSE_ID using the Programmable Search Engine. Here you need to specify your designated wesbite.
Link: https://programmablesearchengine.google.com/controlpanel/create
I only want information coming from Vinmec Health News, thus, my setup is as below:
2. Install necessary packages and libraries
!pip install openai
!pip install langchain
!pip install faiss-gpu # For CUDA 7.5+ Supported GPU's.
!pip install html2text
!pip install tiktokenfrom langchain.chat_models import AzureChatOpenAI
from langchain.vectorstores import FAISS
from langchain.docstore import InMemoryDocstore
from langchain.embeddings import OpenAIEmbeddings
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.retrievers.web_research import WebResearchRetriever
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain3. Innitialize Large Language Models
We will utilize two LLMs:
GPT4-32k as our search query and chat engine
text-embedding-ada-002 as our embedding model
#initialize LLM object
llm = AzureChatOpenAI(
deployment_name="your deployment name",
model_name="gpt-4-32k",
openai_api_key='your OpenAI API key',
openai_api_version = '2023-06-01-preview',
openai_api_base='your Azure Open AI endpoint'
)
# initialize embeddings object
embed = OpenAIEmbeddings(
deployment="embeddings",
model="text-embedding-ada-002",
openai_api_key='your OpenAI API key',
openai_api_version = '2023-06-01-preview',
openai_api_base='your Azure Open AI endpoint'
)4. Initialize our vectorstore database
We will use FAISS as our vectorstore database and semantic search. FAISS, short for "Facebook AI Similarity Search," is a powerful open-source library designed for efficient similarity search and clustering of large datasets. Developed by Facebook AI Research, FAISS is widely used in various applications. It provides a range of indexing methods optimized for both CPU and GPU, enabling rapid and accurate retrieval of nearest neighbors from massive datasets.
You can read more about FAISS at: https://faiss.ai/index.html
# Initialize the vectorstore
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embed.embed_query, index, InMemoryDocstore({}), {})5. Intialize our search engine
GoogleSearchAPIWrapper is a convenient and user-friendly Python library that simplifies the process of interacting with the Google Search API. With this wrapper, developers can effortlessly integrate Google Search capabilities into their projects by utilizing its intuitive functions and methods.
#Initialize our search engine
search = GoogleSearchAPIWrapper(
google_api_key = 'your google api key',
google_cse_id = '16c9d0e3718d2408e'
)6. Split documents before sending to LLM
Let's say that I search for keyword "headache" and the agent has found all 3 articles related to headache. It then scrapped all the texts from the articles to send to LLM for embeddings. However, before we can send the documents to LLMs, we need to cut them into chunks. The code below will help you configure the length of text chunks to send to LLMs. Note that the maximum number of chunks you can send to OpenAI API in one API calls is only 16.
#Configure how you want to spilt the docs before sending to llm
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 3000,
chunk_overlap = 300,
length_function = len,
is_separator_regex = False)7. Setting up our WebRetriever and QnA agent
Let's talk a bit about Langchain WebRetriever. Langchain WebRetriever is a tool for web research based on the Google Search API.
It uses an LLM to generate multiple relevant search queries, executes a search for each query, and then extracts information from the top results.
The results are then indexed into a vectorstore and ranked according to their relevance to the original query.
Here is how we can set it up for our project:
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore,
llm=llm,
search=search,
text_splitter = text_splitter,
num_search_results = 3
)Next, we will use RetrievalQAWithSourcesChain to combine information from various articles on Vinmec websites and answer users' inquiries:
RetrievalQAWithSourcesChain first retrieves a set of documents that are relevant to the query, and then uses a language model to answer the question based on the retrieved documents.
It also returns the sources of the retrieved documents, which can be helpful for debugging or understanding the answer.
Here is how you can set it up:
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm,
retriever=web_research_retriever)Finally, we will build a function that take user's input and generate answer:
def get_response(user_input):
result = qa_chain({"question": user_input})
return result['answer'] + "\n" + "Source: " + result['sources']Now our chatbot backend is readyyy! We can build a simple frontend for it and make it alive. Below code is how I build the frontend with Streamlit:
import streamlit as st
import random
from streamlit_chat import message
import import_ipynb
from Medical_ChatBot import get_response
st.write('Hello, how are you today? :sunglasses:')
st.header("I'm your Medical Chatbot!")
st.markdown("Ask your health-related questions here. ")
def process_input(user_input):
response = get_response(user_input)
return response
# Initialize session_state if it doesn't exist
if "past" not in st.session_state:
st.session_state["past"] = []
if "generated" not in st.session_state:
st.session_state["generated"] = []
if "input_message_key" not in st.session_state:
st.session_state.input_message_key = str(random.random())
chat_container = st.container()
user_input = st.text_input("Type your message and press Enter to send.", key= st.session_state.input_message_key)
if st.button("Send"):
response = process_input(user_input)
st.session_state["past"].append(user_input)
st.session_state["generated"].append(response)
st.session_state["input_message_key"] = str(random.random())
st.experimental_rerun()
if st.session_state["generated"]:
with chat_container:
for i in range(len(st.session_state["generated"])):
message(st.session_state["past"][i], is_user=True, key=str(i) + "_user")
message(st.session_state["generated"][i], key=str(i))Conclusion
This article discussed the development of a medical chatbot designed to address general health-related questions using a diverse array of information from over 3000 health articles on the Vinmec website. The utilization of cutting-edge technologies, including GPT-4 and LangChain, showcased the potential of artificial intelligence and natural language processing in revolutionizing the way we access medical insights.
Challenges and Cautions: However promising the medical chatbot may be, it's important to acknowledge certain challenges and exercise cautions. The reliance on web research introduces potential biases or inaccuracies in the information collected from online sources. Medical advice and diagnoses should never replace professional medical consultation, and users must be educated to differentiate between general information and personalized medical guidance. I have noticed the chatbot gives slightly different answers on the same question, or mixing between English and Vietnamese in some instances. Thus, there is definitely room for further exploration and finetuning. Moreover, ensuring data privacy and complying with ethical guidelines are crucial, as medical data carries a high level of sensitivity.
References
LangChain. (2023b). Automating web research. LangChain.
https://blog.langchain.dev/automating-web-research/
WebResearchRetriever | ️🔗 Langchain. (n.d.-b). https://python.langchain.com/docs/modules/data_connection/retrievers/web_research


Comments